JustGRPO:扩散语言模型的极简主义回归
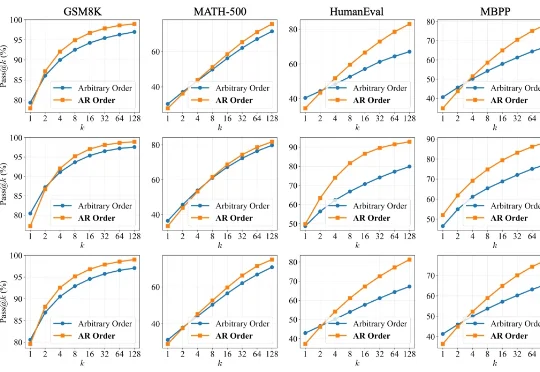
JustGRPO:扩散语言模型的极简主义回归扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。
来自主题: AI技术研报
11094 点击 2026-01-29 14:55
 搜索
搜索
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。
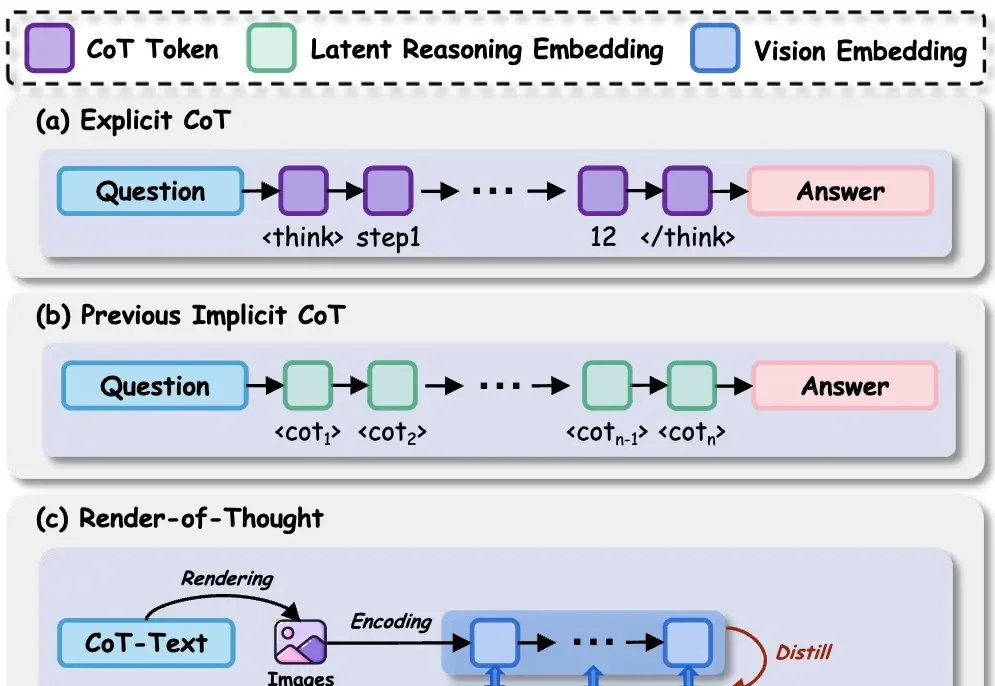
在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。
2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。

简单到难以置信!近日,Google Research一项新研究发现:想让大模型在不启用推理设置时更准确,只需要把问题复制粘贴再说一遍,就能把准确率从21.33%提升到97.33%!
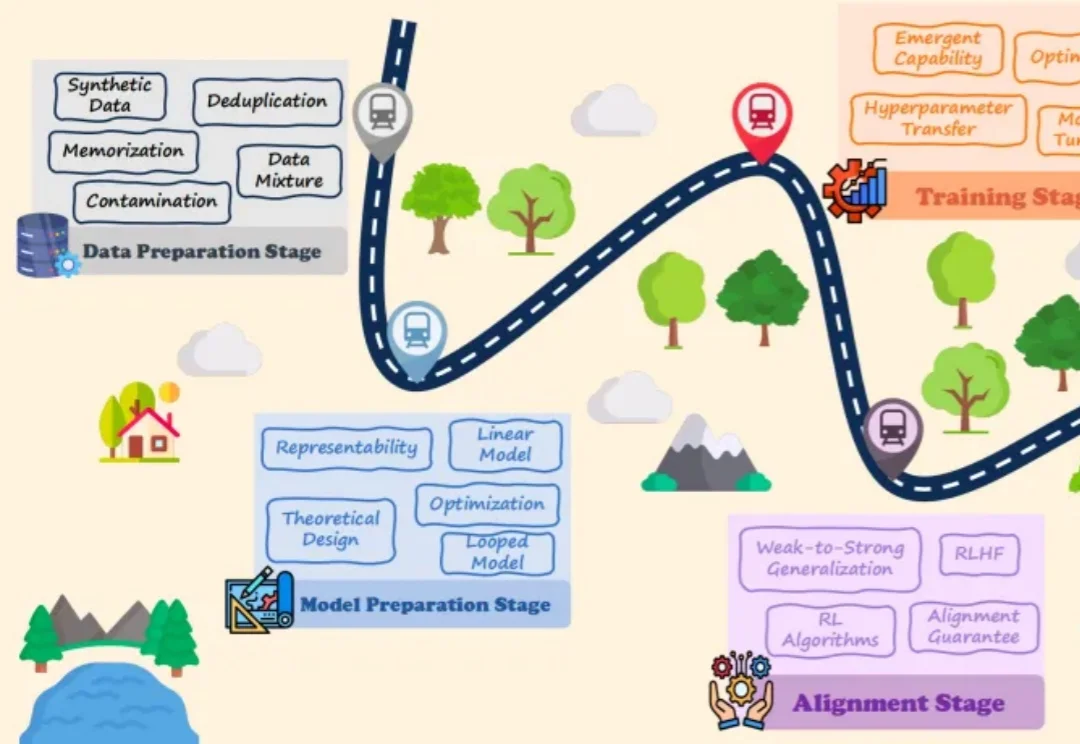
大语言模型(LLMs)的爆发式增长引领了人工智能领域的范式转移,取得了巨大的工程成功。然而,一个关键的悖论依然存在:尽管 LLMs 在实践中表现卓越,但其理论研究仍处于起步阶段,导致这些系统在很大程度上被视为难以捉摸的「黑盒」。
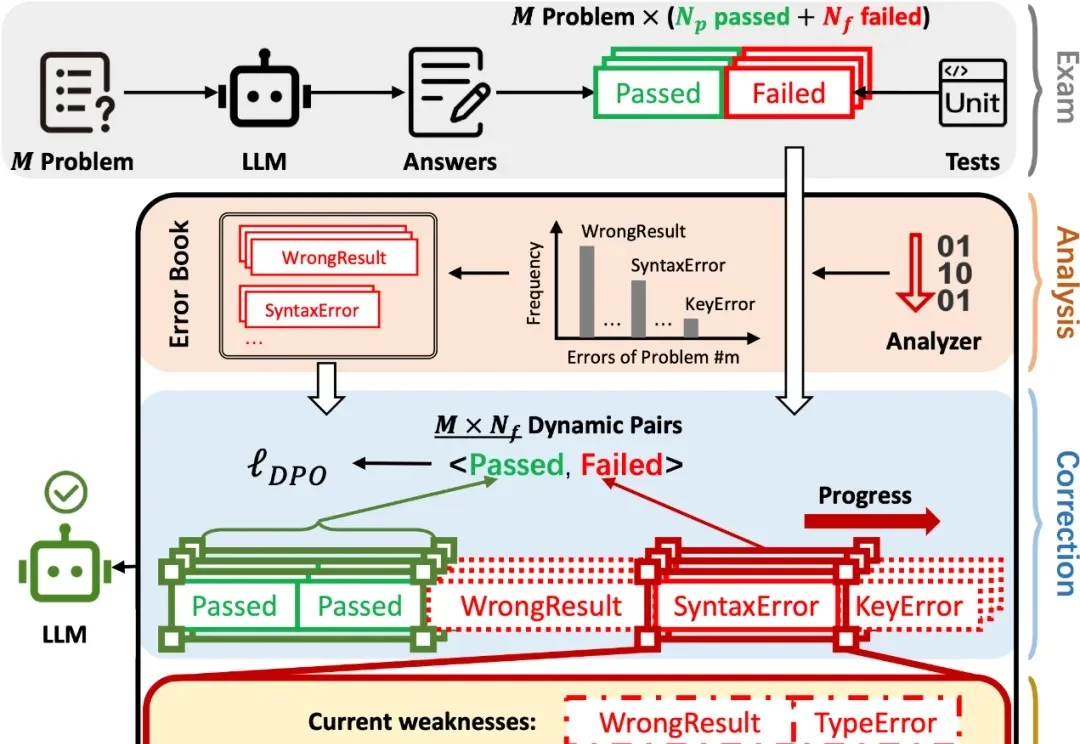
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。
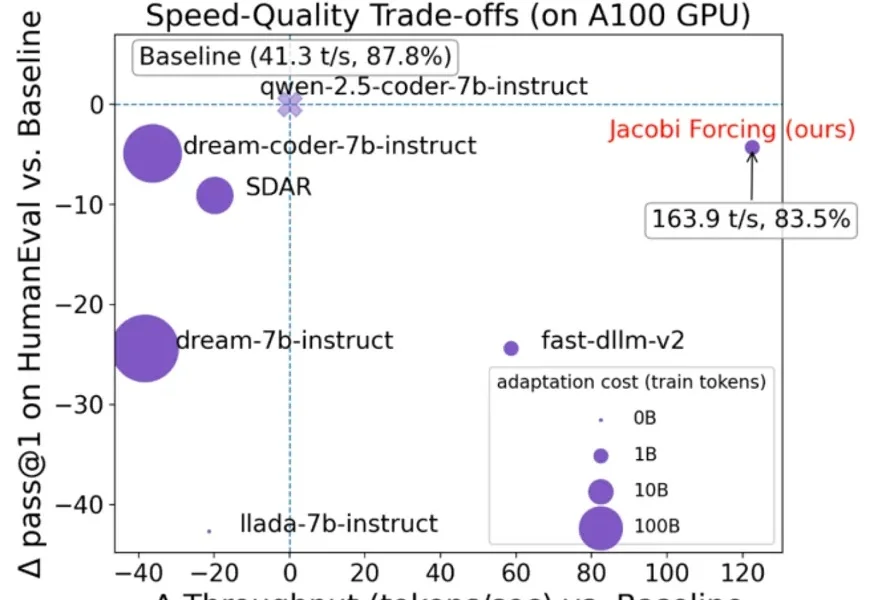
在大语言模型(LLM)落地应用中,推理速度始终是制约效率的核心瓶颈。传统自回归(AR)解码虽能保证生成质量,却需逐 token 串行计算,速度极为缓慢;扩散型 LLM(dLLMs)虽支持并行解码,却面
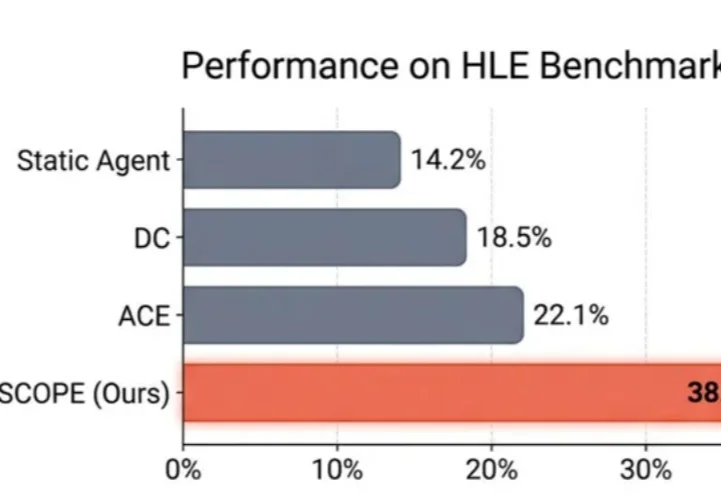
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。
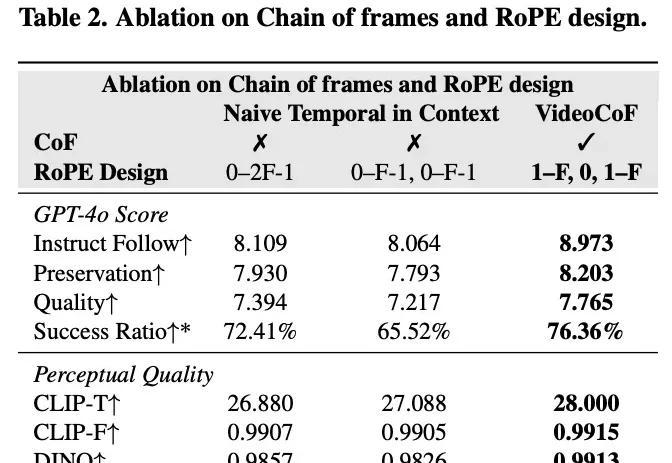
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!